OCR(Optical Character Recognition)在文字识别阶段,使用基于深度学习的端到端的方案,将文字识别转化为序列学习的问题,我们采用CRNN+CTC,本文主要记录在文字对齐时采用的CTC算法。
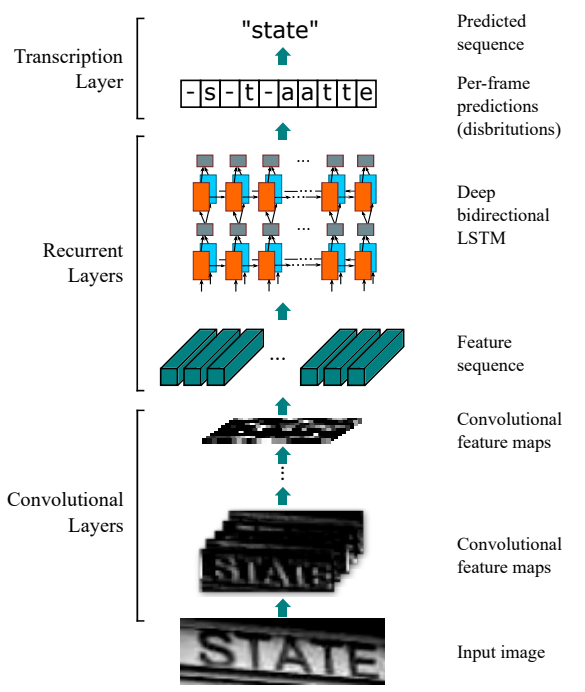
CRNN模型大致流程描述如下图1,Transcript Layer就是我们使用CTC算法实现的过程,目的是在预测时从循环层获取的sequence分布通过去重整合等操作转换成文字标签。
在应用上的衔接
来看OCR上对此算法的应用,CRNN借鉴了语音识别中的LSTM+CTC的建模方法,不同点是输入进LSTM的特征,从语音领域的声学特征(MFCC等),替换为CNN网络提取的图像特征向量。CRNN算法最大的贡献,是把CNN做图像特征工程的潜力与LSTM做序列化识别的潜力,进行结合。它既提取了鲁棒特征,又通过序列识别避免了传统算法中难度极高的单字符切分与单字符识别,同时序列化识别也嵌入时序依赖(隐含利用语料)。
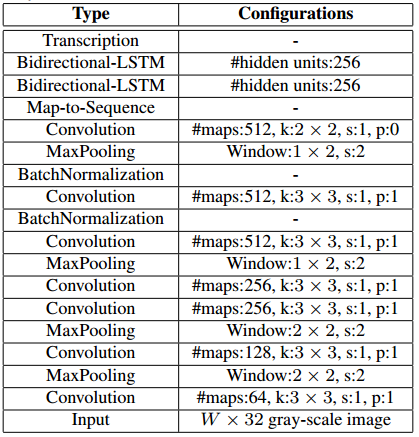
CNN使用VGG16提取特征图,输入32 * w归一化高度的词条图像(图像高度h必须统一为32个像素,由卷积特征决定),输入保持图像尺寸比例,解决字符拉伸导致识别率降低的问题。输出特征向量1 * w/4 * 512,把特征图按列切分(Map-to-Sequence),每一列的512维特征,输入到两层各256单元的双向LSTM进行分类,卷积特征图的尺寸(w/4)动态决定LSTM时序长度。。在训练过程中,通过CTC损失函数的指导,实现字符位置与类标的近似软对齐。
使用该算法的原因
解决图片上字符位置与标签对齐的问题,试想一下,例如我们要训练上图中Input image图片样本,那我的标签需要标注“STATE”,并且需要标注哪部分像素对应“S”,哪部分像素对应“T”。采用这样的“分割”方式 我们很难获取到包含输入序列和输出序列映射关系的大规模训练样本(人工标注成本巨高,且启发式挖掘方法存在很大局限性)。那有什么算法能解决所面临的标注问题呢?我们引用CTC。
Connectionist Temporal Classification(CTC)是Alex Graves等人在ICML 2006上提出的一种端到端的RNN训练方法,它可以让RNN直接对序列数据进行学习,而无需事先标注好训练数据中输入序列和输入序列的映射关系,使得RNN模型在语音识别等序列学习任务中取得更好的效果,在语音识别和图像识别等领域CTC算法都有很比较广泛的应用。总的来说,CTC的核心思路主要分为以下几部分:
- 扩展了RNN的输出层,在输出序列和最终标签之间增加了多对一的空间映射,并在此基础上定义了CTC Loss函数。
- 借鉴了HMM(Hidden Markov Model)的Forward-Backward算法思路,利用动态规划算法有效地计算CTC Loss函数及其导数,从而解决了RNN端到端训练的问题
- 结合CTC Decoding算法RNN可以有效地对序列数据进行端到端的预测
CTC的原理,如何解决标注问题
发现很难去解释为什么使用该算法,但是我们不妨先抛开摆在面前的问题,先来理解CTC的原理,然后套用原理来解决问题。其实最后就是一两句话,你会发现算法如何解决该问题。