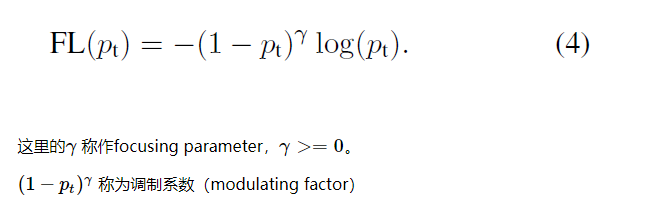balanced cross entropy
训练时正负样本数目相差较大,常见的做法就是给正负样本加上权重,给数量较少的正样本的loss更大的权重,减小负样本loss的权重。
主要用于FCN/U-net等分割,边缘检测的网络,用于对像素级别的2分类样本不平衡进行优化。
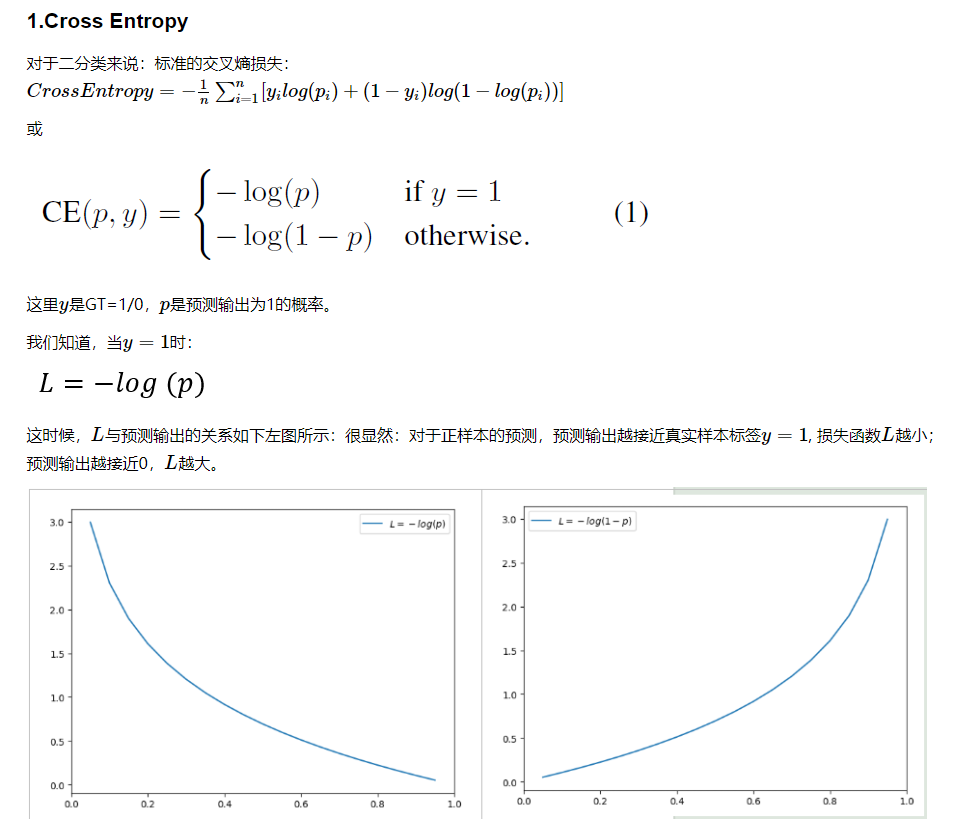
sigmoid_cross_entropy公式:
-y_hat * log(sigmoid(y)) - (1 - y_hat) * log(1 - sigmoid(y))
class_balanced_sigmoid_cross_entropy公式:
-β * y_hat * log(sigmoid(y)) -(1-β) * (1 - y_hat) * log(1 - sigmoid(y))
思想就是引入新的权值β,实现正负样本loss的平衡,从而实现对不同正负样本的平衡。

focal loss
论文:Focal Loss for Dense Object Detection
论文链接:https://arxiv.org/abs/1708.02002
作者认为one-stage detector的准确率不如two-stage detector的原因是:样本的类别不均衡导致的。在object detection领域,一张图像可能有成千上万的负样本像素,但是其中只有很少一部分是包含正样本像素,这就带来了类别不均衡。
那么类别不均衡会带来什么后果呢?引用原文讲的两个后果:(1) training is inefficient as most locations are easy negatives that contribute no useful learning signal; (2) en masse, the easy negatives can overwhelm training and lead to degenerate models. 什么意思呢?负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。
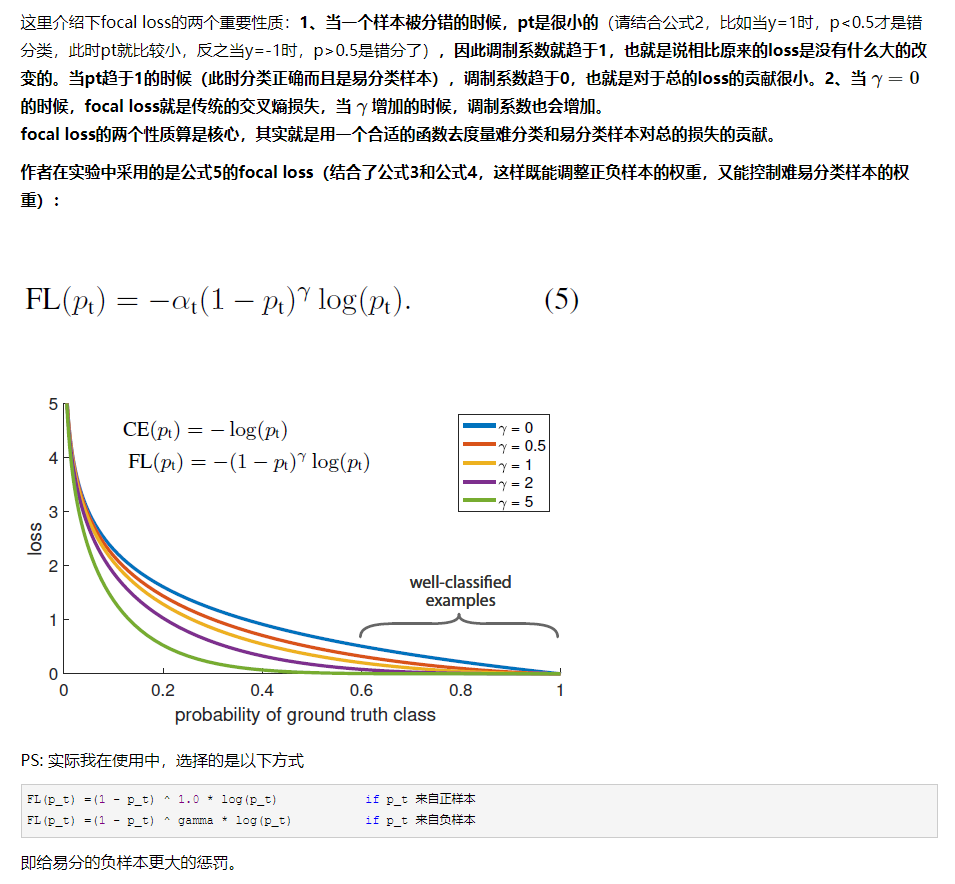
作者提出一种新的损失函数:focal loss,这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。为了证明focal loss的有效性,作者设计了一个dense detector:RetinaNet,并且在训练时采用focal loss训练。实验证明RetinaNet不仅可以达到one-stage detector的速度,也能有two-stage detector的准确率。

focal loss 公式